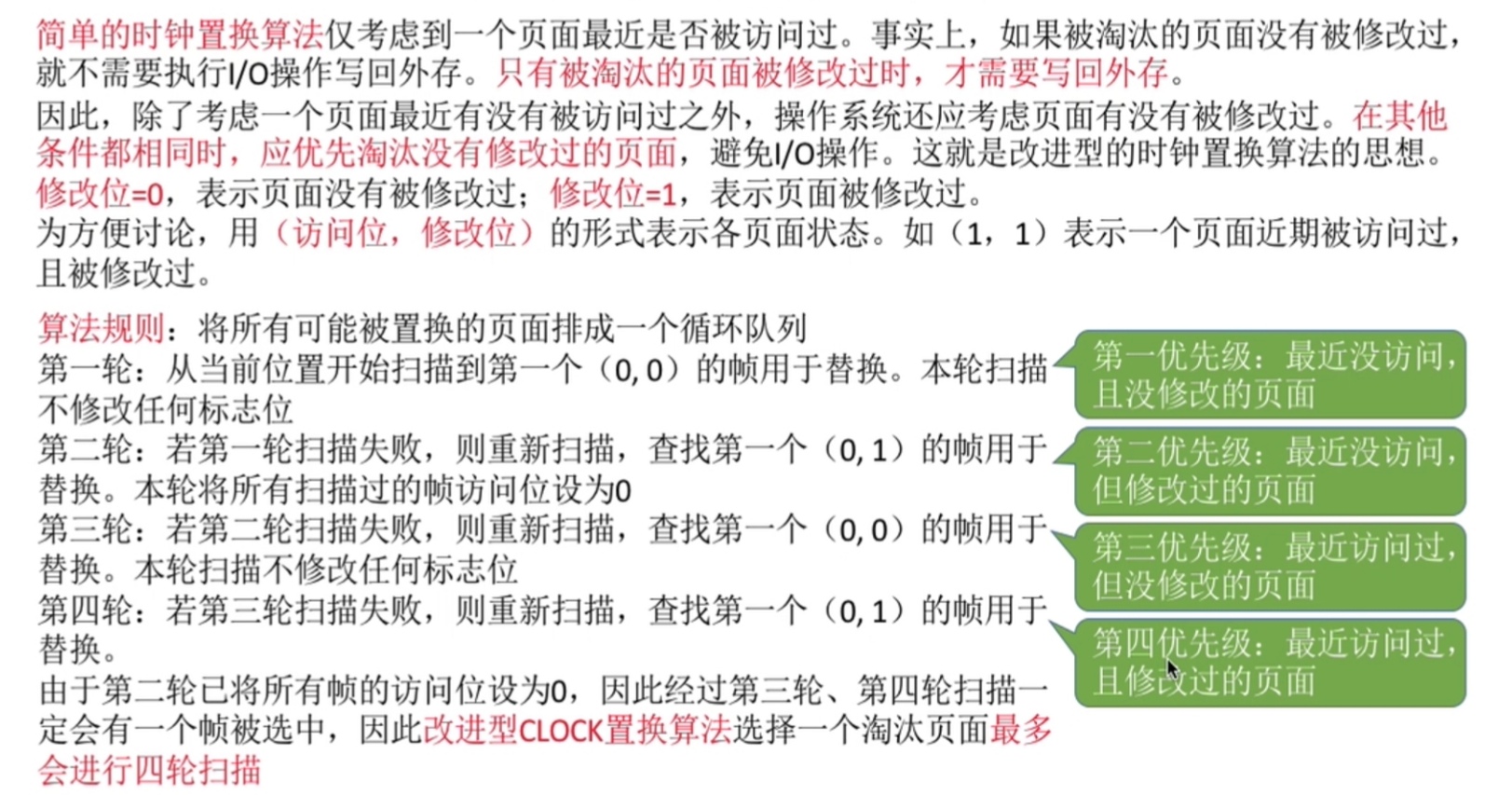
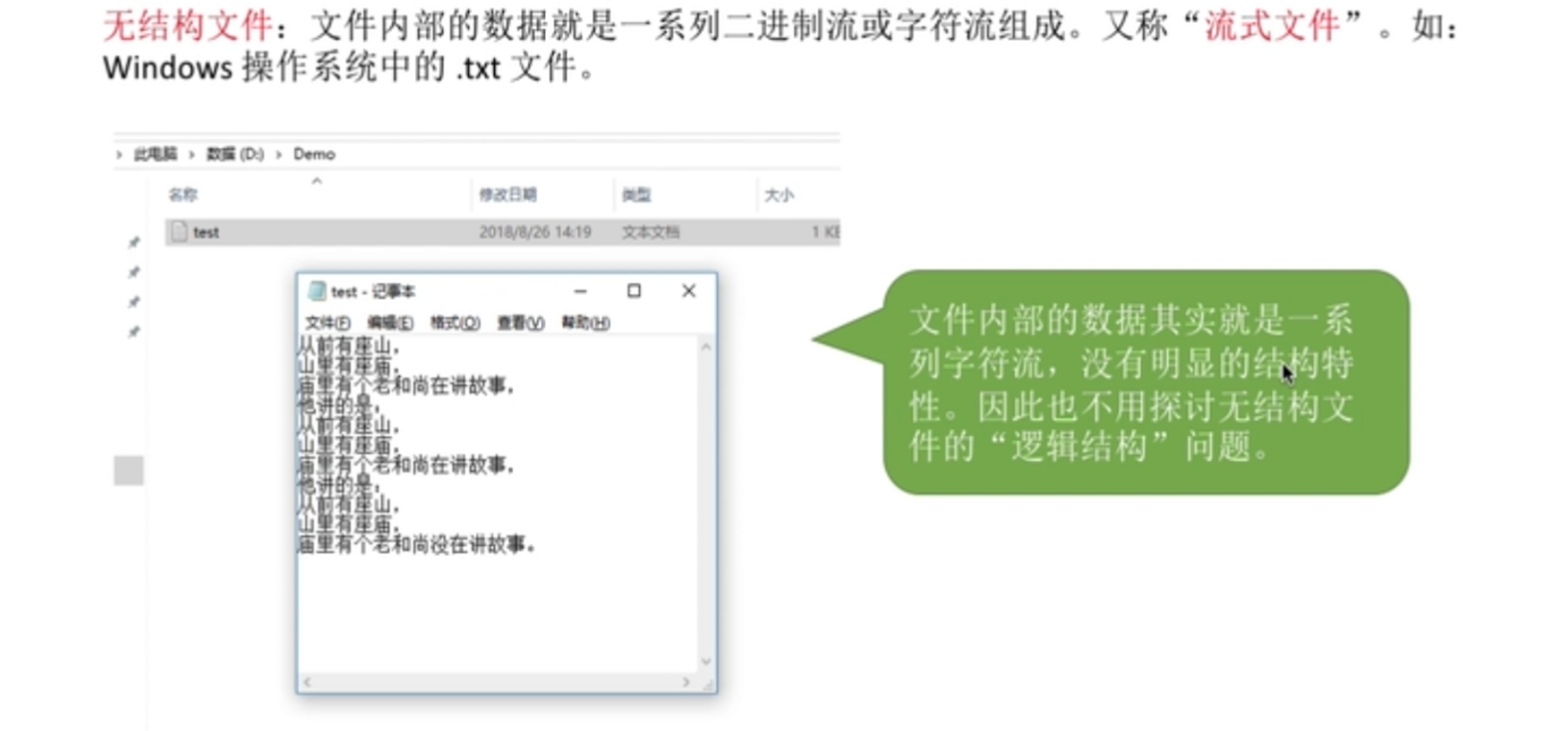
- 无结构文件
- 有结构文件
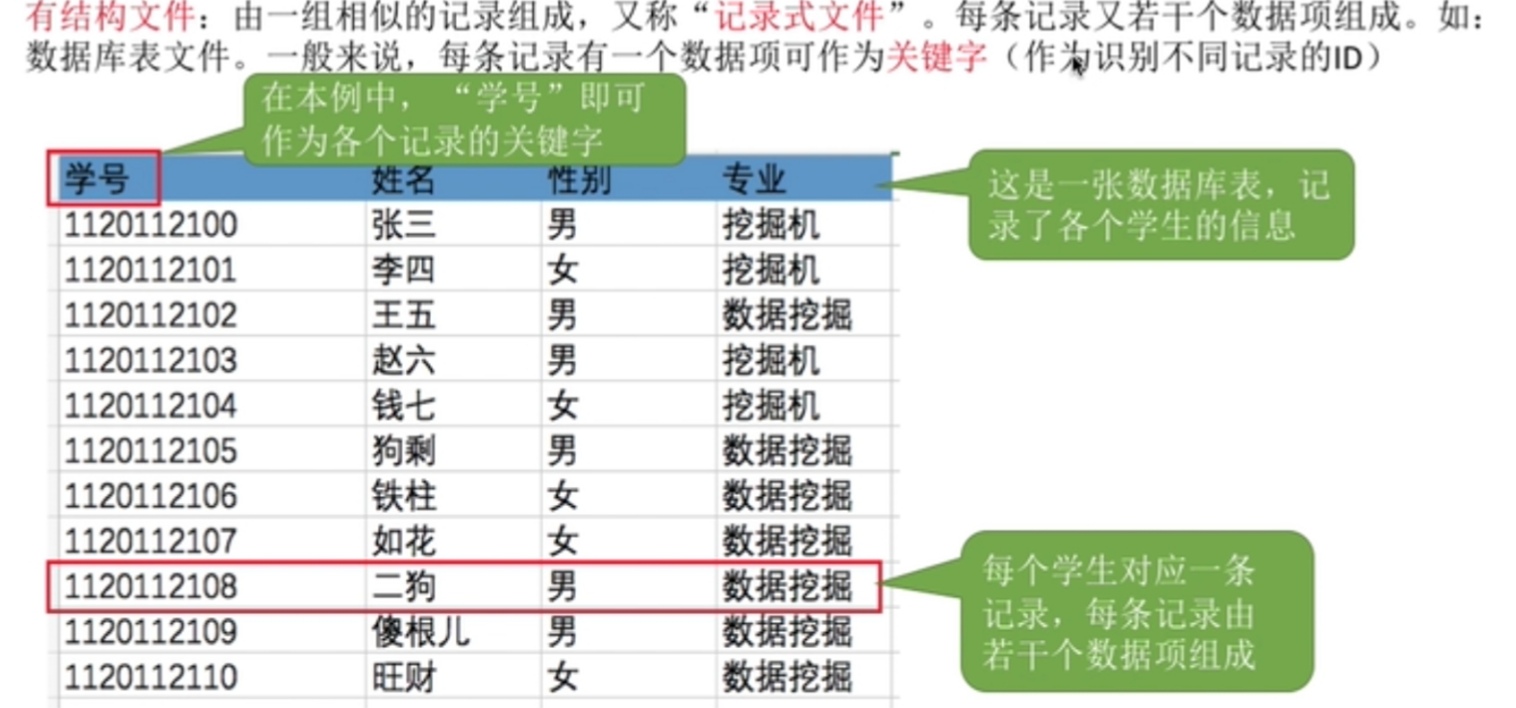
根据各条记录长度是否相等,可将记录划分为定长记录及可变长记录
比如专业大家都差不多,就是定长,但是换成特长,可能有的人很多,有的人没有,就是可变长
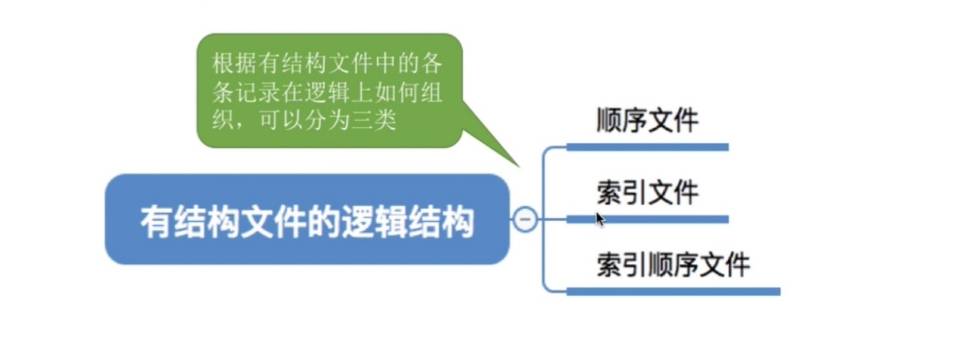
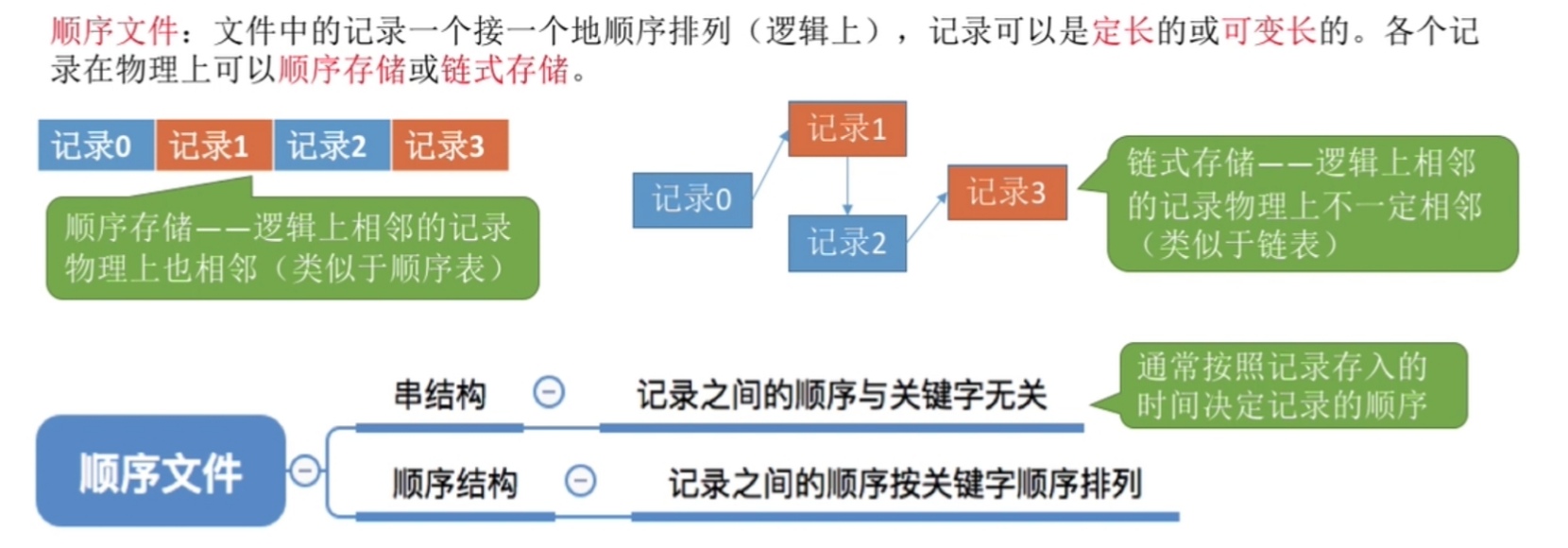
因此组合一下,顺序文件就有以下分类

链式存储,就像链表他是不能想要第几个节点就能马上得到的,必须从第一个开始遍历
顺序存储中可变长记录的话,没有特定的规律,不能通过简单地计算直接得到物理位置,因而也只能从第一个开始遍历
定长记录的话就类似于数组了,当然可以随机存取,特别地,如果使用串结构,则各记录不是按照关键字顺序排列的,就无法迅速查找到某关键字对应的记录;而如果是顺序结构,即根据关键字按顺序排列,就可以用折半查找(二分法),就是从中间的那条记录与要查找的记录比较,再就根据升序或者降序向前或向后查找。
一般情况下顺序文件都是指顺序存储
但顺序文件的缺点是删除或增加一个记录很困难,但如果是串结构就相对简单了,因为他不是按关键字顺序的所以添加直接加在后面就行,删直接删就行不用考虑顺序问题
虽然定长记录查找起来更快一些,但现实使用更多的是可变长的,那该怎么办呢?
这就引出了索引文件(适用于对信息处理的及时性要求很高的场合)
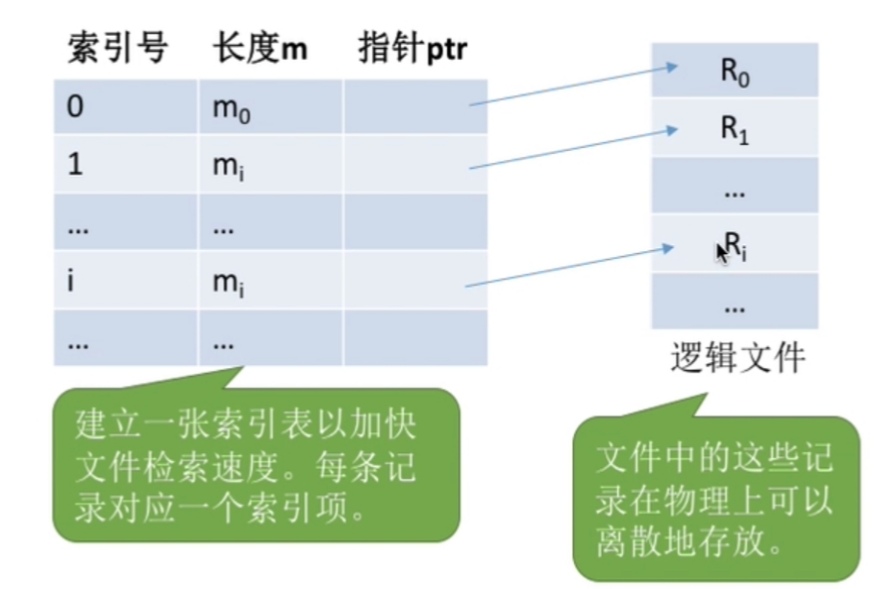
索引表得连续的放在内存里,逻辑文件(不定长记录文件)可离散着放,这样的话索引表就相当与定长记录的顺序文件,就可以迅速找到第i个的地址,同时如果是按关键字排列,可以用折半查找的方法加快访问速度;
索引号可以替换成关键字,比如学号,姓名…
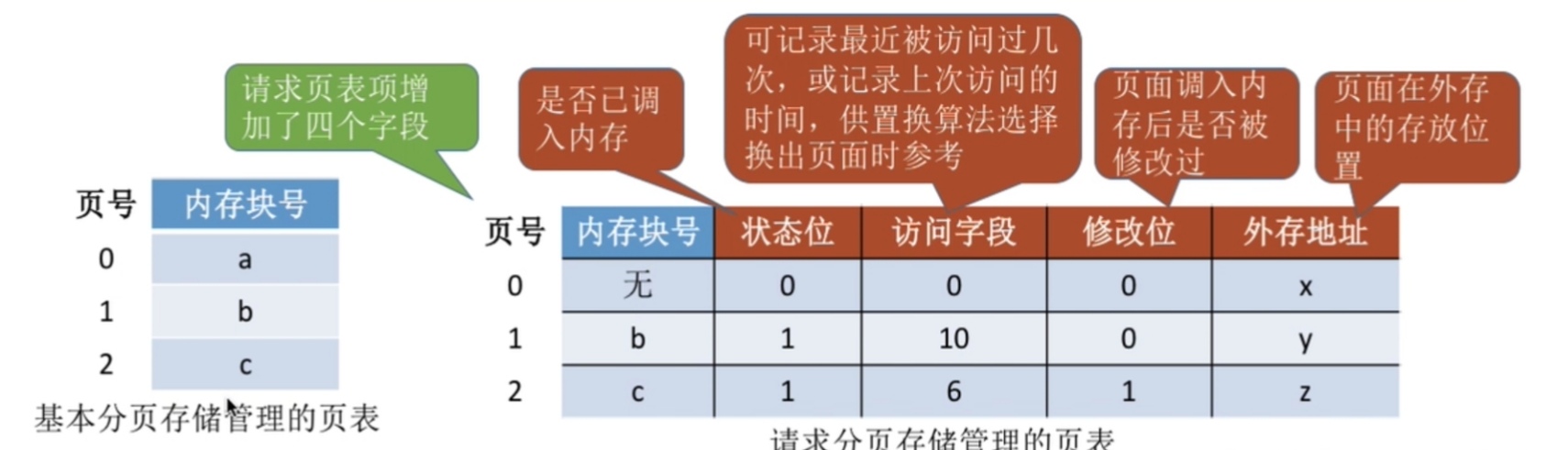
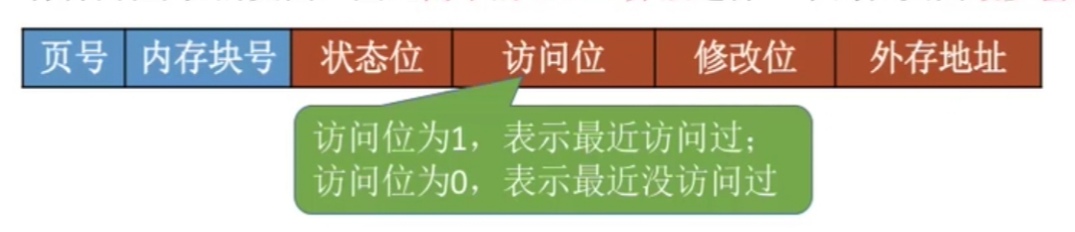
索引表的每个表项长度相同,联想前面的页表项
如果索引表的表项占得地方太大了,比如说文件的记录平均占8B,但每个索引表项却占32个字节,那索引表占的空间就比文件本身4倍,那这样内存的利用率就会大大降低
为了解决这个问题就引出了索引顺序文件
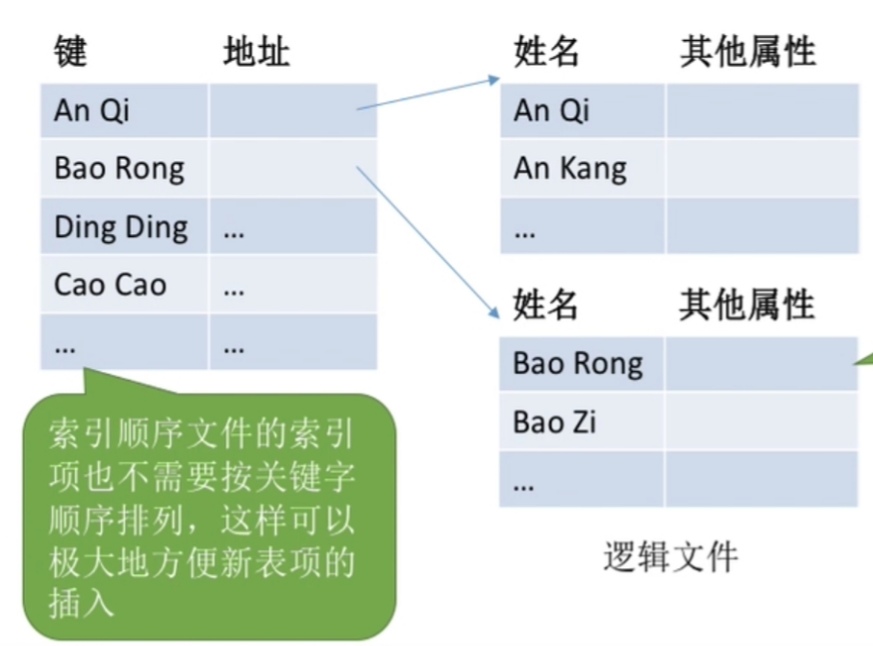
如上图所示,将文件分组,每一组对应索引顺序文件的一个索引表项,这样的话跟一对一相比,当然节省了很多空间,还有索引顺序文件的项不是按关键字排列,这样增加删除就更快了
那现在索引表确实是瘦了不少,那他是不是可以解决查找速度慢的问题呢
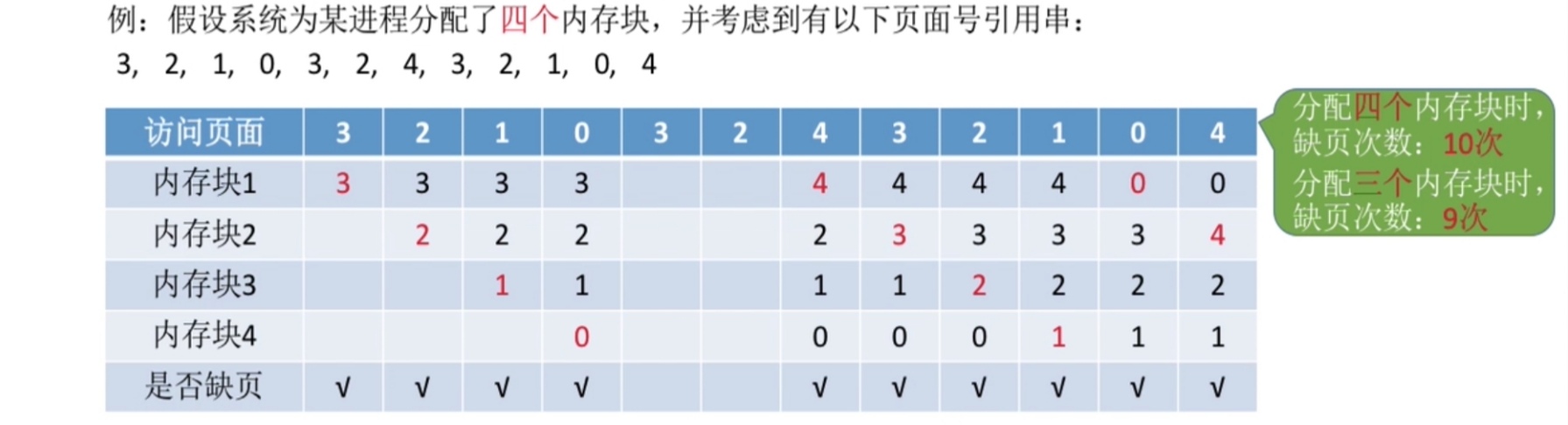
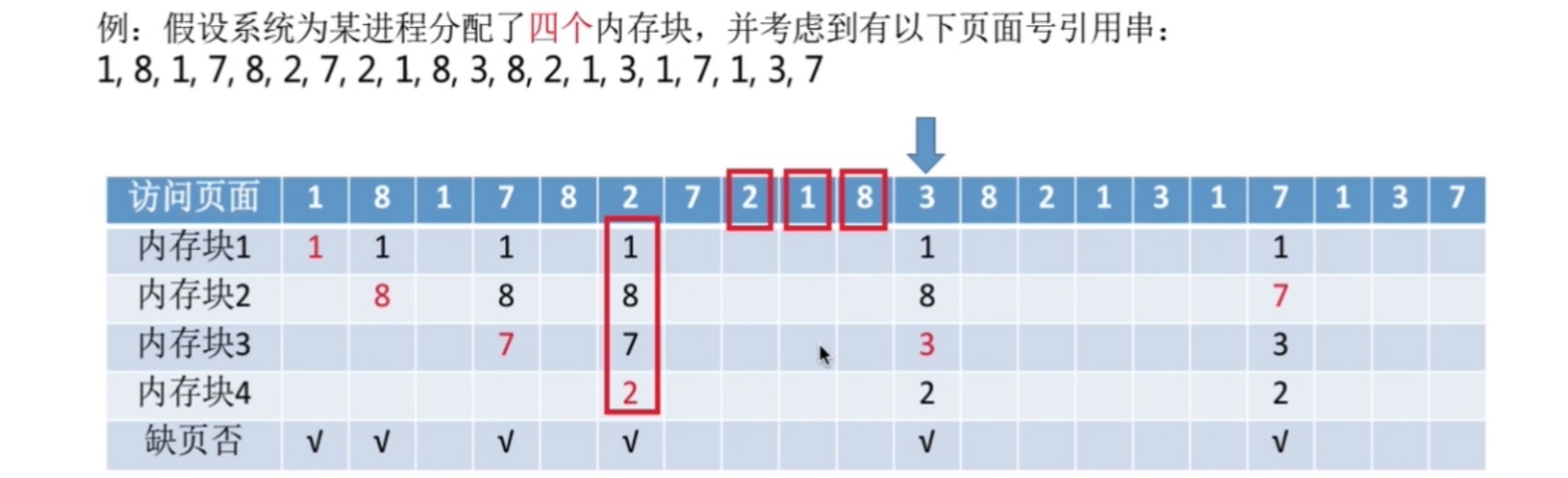
假如一个顺序文件有10000个记录,则按关键字检索,只能从头开始(不是定长),则至少5000次
但如果用索引顺序表,假设将这10000条记录分成100组,则每组有100条记录,当要查找是肯定要先去索引顺序表找在哪个组,从头开始找,平均要50次,找到在哪一组之后,就要去对应的组找到具体的位置,一组有100条,那平均就要找50次;查找速度就是50+50=100次
由此看来,的确是减少了不少
但如果文件有10的6次方个记录,可分为1000组,每组1000个记录,这样平均要500+500=1000次才能找到,还是很大,那该怎么办呢
可以建立多级索引顺序表
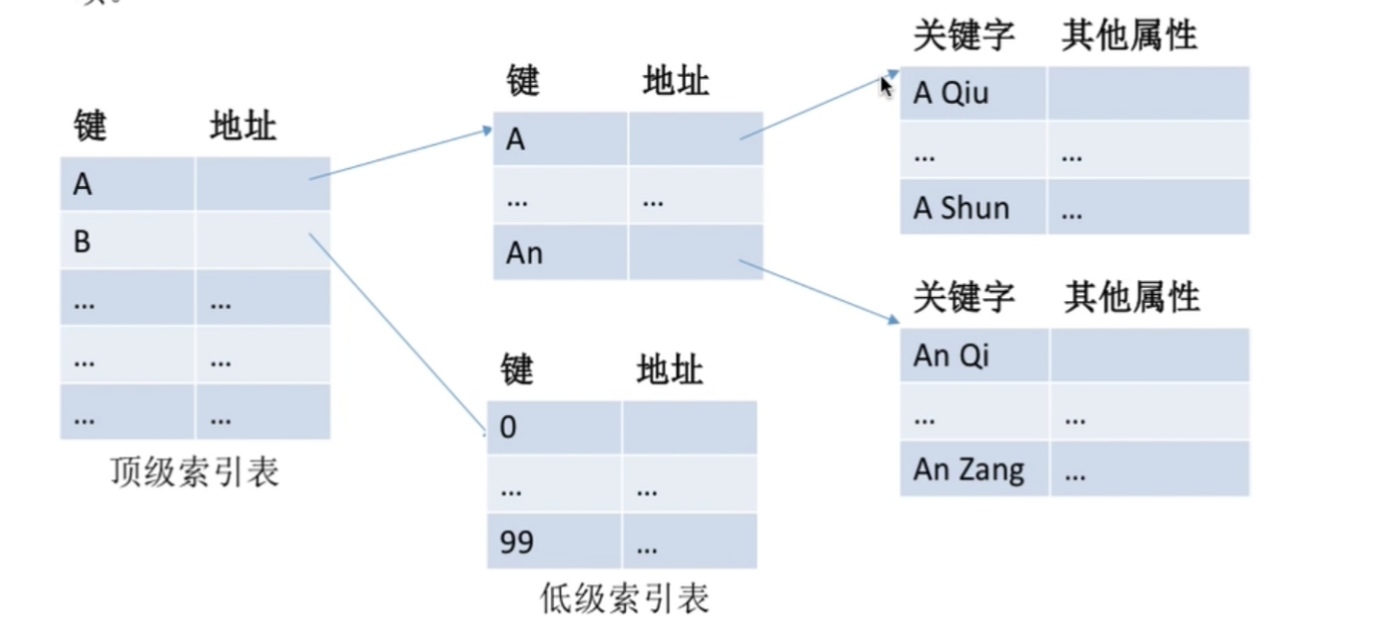
就用上面的10的6次方的例子,这样就是拿出100组,每一项对应一组(100项),再对应一组(100项)
这样访问次数就是50+50+50=150,相比于1000少了很多